
The Cognitive Load Theory is both a mental model of how the human mind works when learning and a set of training guidelines to improve teaching. John Sweller created the Cognitive Load Theory. He is an Australian educational psychologist currently teaching in the University of New South Wales as Professor Emeritus.
- The 3 key resources for learning in the Cognitive Load Theory
- Key concepts of the Cognitive Load Theory
- Optimizing intrinsic load in Cognitive Load Theory
- Reducing Extraneous Load in Cognitive Load Theory
- What’s next? Learn more on training, then coaching and change management
- Do you want to learn more about the Cognitive Load Theory? Here are some valuable references
The 3 key resources for learning in the Cognitive Load Theory
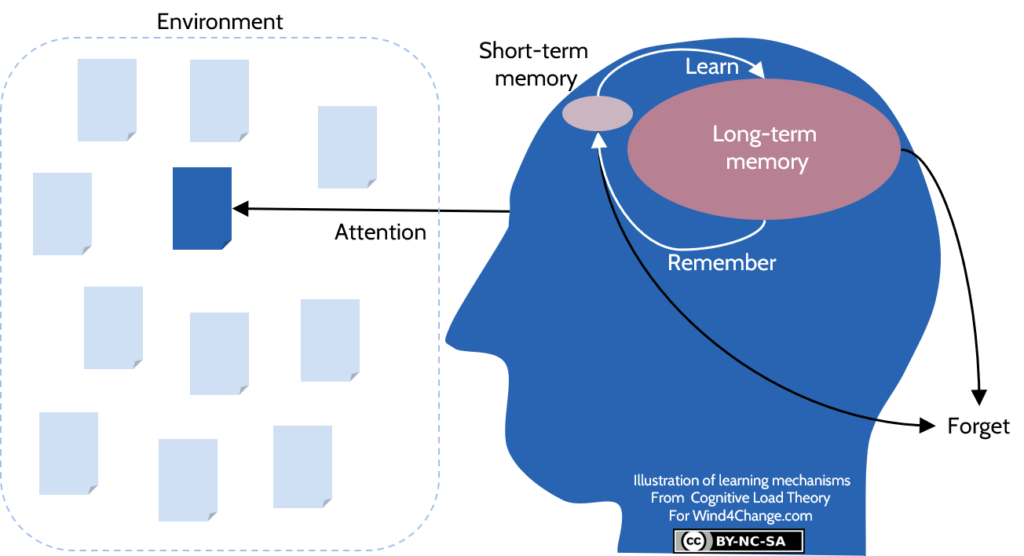
- The environment stands for everything that is outside of our mind. For instance, Internet, books, or the knowledge of co-workers. For sure, the environment is an infinite external storage of information.
- The long-term memory is where we keep all our memories. In detail, this covers life events (episodic knowledge), factual information (semantic knowledge) and memories of processes, in other words, how to do something (procedural knowledge). Until now, searchers have not found a limit to long-term memory for our current lifetime. As a result, long-term memory is also an infinite internal storage of information.
- The short-term memory or working memory is the place of our mind where thinking takes place. In contrast to the environment and the long-term memory, the working memory is limited between 4 to 7 pieces of information at the same time. To put it differently, we can have only from 4 to 7 elements in mind at the same moment. Clearly, our working memory is the bottleneck, the limitation of our thinking system.
The concept of load in Cognitive Load Theory stances for anything that takes from our working memory capacity. As a consequence, the core guidance of Cognitive Load Theory is to reduce cognitive load in order to increase learning.
Key concepts of the Cognitive Load Theory
Primary versus secondary knowledge
The Cognitive Load Theory sorts knowledge in 2 categories:
- Primary knowledge is the knowledge that is either part of our biology and our evolution. Learning and using biologically primary knowledge is unconscious, fast and without effort:
- The capacity to interact with our environment. For instance, to listen and speak, recognize faces, engage in basic social functions.
- The ability to reach a level of abstraction to go beyond our environment. For example, to transfer knowledge previously acquired to new situations or make plans for potential future events.
- Secondary knowledge is the knowledge on the contrary that we learn consciously. To learn it and use, it is slow and it requires effort. Truly, this is why education was created for us to acquire this secondary knowledge.
Domain of knowledge
There are 2 kinds of domain of knowledge in the Cognitive Load Theory:
- Domain-general skills and knowledge relate to general capabilities that apply to a wide range of tasks and are widely transferable. To illustrate, work skills such as critical thinking, problem solving, brainstorming, communication and teamwork fall in this category.
- On the contrary, domain-specific skills and knowledge apply only in a specific domain, for example literature, history or music.
And this is the main difference between novices and experts in given domain. For sure, experts have a greater amount of domain-specific knowledge. As a result, experts can use knowledge but novices need to use thinking skills. So this explains why when teaching, the trainer should consider the number of elements that are the source of cognitive load accordingly to the level of the expertise of the audience. As a matter of fact, trainees have to learn elements progressively to incorporate them into their long-term memory. Doing so, they will be able to face more complexity and grow expertise.
Element of information
Undoubtedly, the more elements of new information trainees have to process in their working memory, with in addition the more complex the relations between these elements, the more difficult the learning will be. Definitively, the level of interactivity between elements is a key parameter to optimize learning:
- Knowledge with low element interactivity can be learned in isolation.
- On the contrary, knowledge high in element interactivity requires multiple elements at the same time for learning to happen.
Chunking is a phenomena that comes when expertise is growing as trainees manage to combine multiple small elements into a large element within long-term memory. As a result, they can process more and more complex thoughts. Surely, this explains why new information requires more working memory capacity than familiar one.
Therefore, if a material is too high in element interactivity, it is the trainer’s job to adapt the learning ambition to the working memory limit of the trainees.
The 3 types of cognitive Load
Cognitive Load is composed of 3 types of load relatively to the learning intention:
- Intrinsic cognitive load is related to the elements that are part of the DNA of the knowledge to be learned. Without them learning of the core concepts and skills cannot occur. Consequently, the trainer want them to be the primary use of the trainee’s working memory.
- Instead, extraneous cognitive load comes from the way the information is presented to trainees. For sure, the trainer want to minimize this load. Indeed, the total cognitive load is the sum of intrinsic and extraneous load. In other words, intrinsic and extraneous load taken together cannot exceed the trainee’s working memory capacity for learning to happen.
- At last, the third type of load is the germane cognitive load that stands for the work to store knowledge in the long term memory.
Thus, the core guideline of Cognitive Load Theory is to reduce extraneous load and optimize intrinsic load in order to increase learning.
As a guideline, 7 is the magic number as coined by the psychologist George A. Miller.
The Magical Number Seven, Plus or Minus Two.
Optimizing intrinsic load in Cognitive Load Theory
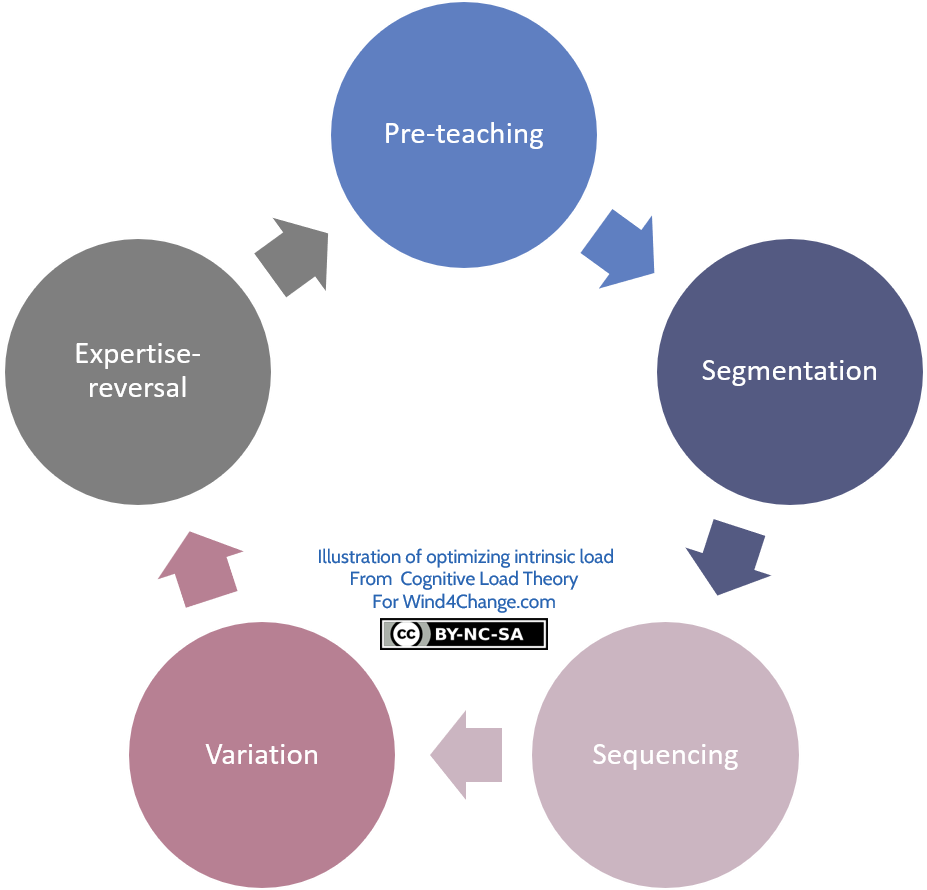
Pre-teaching effect
The principle of pre-teaching is to deliver a piece of the knowledge before the main training then anchoring through multiple reviews over time. As a result, this reduce the trainee’s intrinsic load for the main training. Common examples of pre-teaching are pre-teach vocabulary and pre-teach skills.
Pre-teach vocabulary
New vocabulary is a usual source of high cognitive load for trainees. To illustrate, studies show that trainees need to know 90 to 95% of the vocabulary in a text in order to understand the topic. Hence, the trainer can prepare the audience pre-teaching the vocabulary. To go further, the trainer typically use “bullet-proof definition“. In other words clear definition requiring no pre-requisite knowledge, and illustrate them with examples. Then the trainer anchor vocabulary with multiple reviews.
Pre-teach skills
New tasks to learn may require pre-requisite skills. If the skills themselves are not yet strongly anchored into trainees’ long-term memories, then learning these skills at the same time of learning on how to apply them in a new task will be too much for the trainees’ working memory. So the trainer have to consider pre-teaching required skills to prepare the audience before the training on the new tasks.
Segmentation effect
There is a limit with the number of elements trainees can manage at a time. Therefore, the trainer can reduce this number by breaking the learning into bite-sized pieces. The Cognitive Load Theory call that the isolated element effect. For instance, when playing the piano, the right and left hands must work together with in addition the challenge to manage at the same time the tempo, the rhythm and of course the pitch! In this example, the trainer may have the trainee work only the right hand before considering using both hands at the same time.
Sequencing and combination effect
Here the reduction of complexity is related to the level of zoom of the task to learn. And there are 2 possible approaches both with their benefits, part-whole approach and whole-part approach:
- Part-whole approach aims at building basic skills and knowledge before putting them all together.
- Whole-part approach is to provide general overview then focus learning on segments.
Couple examples of implementation of sequencing and combination:
- Snowball (part-whole): in this approach, the trainer focuses learning iteratively on a new segment in addition to the all previous segments that the trainees will replay for anchoring.
- Simplify conditions (whole-part): here first learning occurs in a simplified, sometimes oversimplified context.
- Manipulate the emphasis (whole-part): in this approach, the trainer will make trainees to focus on some pieces of the task, for instance, critical steps and leave aside more obvious steps.
Variation effect
This training practice is not just a way to reduce intrinsic load but more an optimization of the working memory load. Here the trainer, increases variation, in other words the different cases, the possible options (contextual interference). As a consequence, the learning may require more effort and take more time as the number of interacting elements increase. But with more elements, then more possible comparisons and contrasts, the trainees make more connections and learn more.
Expertise reversal effect
This practice relates to the instruction guidelines. Indeed, instruction guidelines need to make explicit the boundary conditions for the trainees to apply the new knowledge, skills or practices in the proper context. To illustrate the expertise reversal effect, the trainer provides worked examples for novices and proposes problem solving approaches for experts.
Reducing Extraneous Load in Cognitive Load Theory
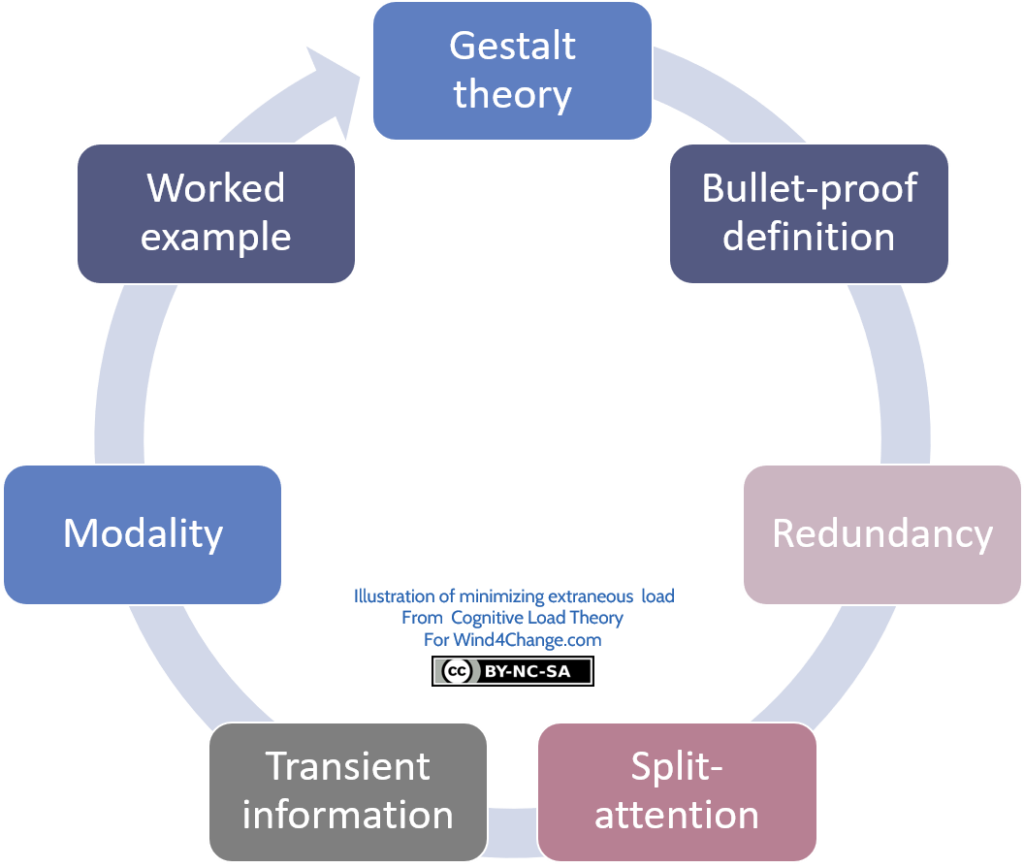
Gestalt theory: how it supports the Cognitive Load Theory
Gestalt is a German word meaning form and it stands in the Gestalt theory as pattern or configuration. The Gestalt theory emerged in Austria and Germany at the beginning of the 20th century as a theory about how human beings perceive their environment. To illustrate, our brain perceives things as a whole, rather than as individual parts. Therefore, our brain looks for patterns and builds links and associations typically based on the layout of lines and shapes.
The Gestalt theory principles
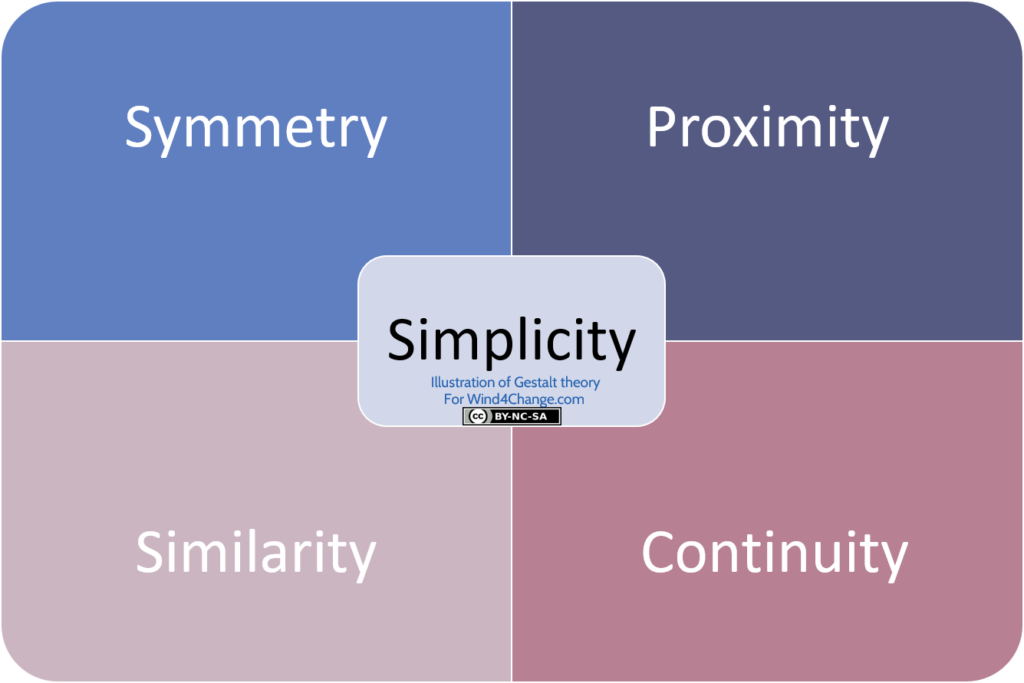
Surely, the trainer should have in mind the basic principles of the Gestalt theory when designing graphic organizers:
- Simplicity: less is more, to have more impact do not provide too many details and overelaborate.
- Symmetry: arrange groups in a systematic way with ordered alignments.
- Proximity: keep close together related elements.
- Similarity: group under themes or heading related items and separate them from items of other themes.
- Continuity: connect related items with lines. Vary thickness of these lines depending on the relative importance of the connection.
The Gestalt theory illustrated
- Thin lines or space for separation.
- No bullet or numbering if possible.
- Limited number of colors.
- No shades or fancy visual effects.
- Icons to illustrate ideas, themes or heading.
- Limited text, just the essential.
- Easy to read font without unnecessary flourishes.
Perfection is achieved, not when there is nothing more to add, but when there is nothing left to take away.
Graphic organizers as an implementation of the Gestalt theory
Typical ways to display information fall in the following patterns:
- Knowledge / recall: for list of items to recall.
- Sequencing: for everything to be ordered like steps, process, chronology. Make sure to limit the number of steps for instance referring to the magical number 7.
- Cause and effect: for items connected with a cause and effect or input / output relationship.
- Similarities and differences: to make comparisons and highlight contrasts.
- Classification: for grouping items related on some aspects.
- Connection: to illustrate items connected.
Bullet-proof definitions
A bullet-proof definition is a one-sentence summary of a key concept or idea. It should be unambiguous and should require no specific knowledge to understand. Truly, starting with too detailed explanations overloads trainees’ working memories. Bullet-proof definitions address the need to provide elements of context to the audience with the minimum level of cognitive load.
In addition, bullet proof definitions support the trainer to keep focus on the core of the training and remove redundancy. Furthermore, the trainer can use these 2 sanity checks when building a training:
- What trainees will be able to do after the training?
- How the trainer will check that?
Related to communication on core concept are acronyms. Without a doubt, avoid them at all costs. Unless you’re absolutely sure that all trainees can automatically decode them and understand what they mean.
Split-attention effect
There is a cost in term of working memory for trainees to integrate information. So the trainer should prevent the split of information either spatially or temporally when trainees have to combine them for learning. The trainer should place them as close as possible in time and space to the actual activity.
Information that must be combined should be placed together in space and time.
Transient information effect
Transient information is information that is not persistent. For instance, when the trainer mentions key points without writing them down. Or when he or she switches to the next slide while the trainees did not capture the core information from the previous one. To put it differently, transient information is present a second then it vanish. As a result, this generates extraneous cognitive load with an effort for the trainees at the level of the working memory to remember or try to remember this transient information.
The trainer can mitigate this issue of transient information effect by providing:
- Small, “remember” boxes on the activity slide.
- Handouts of the training materials.
In addition, it is important to limit the amount of transient information. To illustrate, here are guidelines for the number of key points and instructions:
- Key points: do not overpass 7 key points, with a preference for 5 (the magic number 7 minus 2).
- Instructions: keep instruction less than 3. Actually, trainees need to remember more detail as there are usually sub-clauses within one instruction. More instructions and trainees will forget at least part of the instructions.
Videos and transient information effect
Approach to mitigate the transient information effect with videos is to split them. So trainees have the time to process the information in-between video segments, then as a result increasing learning. A good number is to try to cut videos in segments shorter than 6 minutes.
Classroom discussions and transient information effect
When trainees share relevant information as part of their participation, a key element of pedagogy, this also generates transient information. So, a good way to mitigate this transient information is to have the trainer or one of the trainee write up on the whiteboard the key ideas shared.
Collective working memory effect
Another way to mitigate the transient information effect is to leverage the collective working memory effect. To clarify, trainees remember more when they put their heads together. This relates to Listen-Think-Pair-Share technics: active contribution to understand, explaining to peers and using writing to collect key elements and clarify thoughts. Go go further, we find here key elements that Sharon Bowman developed in Training from the Back of the room.
Redundancy effect
This practice aims as at eliminating all unnecessary information and not replicating necessary information to keep extraneous load to the minimum. To go further, the trainer should pay a specific attention not to replicate information through different communication media.
Redundancy effect with text and spoken word
Language is processed within the part of the working memory that deals with language either spoken or written. So if the communication uses 2 different forms of language, for instance spoken and written, then it gets decoded twice with the 2 decoding processes interfering. Clearly, it is a bad habit for the trainer to read the slides. As it is also a bad habit to have slides where everything is written.
Redundancy effect with images and written words
This phenomena also happens when redundancy is between images and words for instance a commented diagram. So make sure written information is complementary and just supports the diagram.
Redundancy and the expertise-reversal effect
We have seen that the trainer should adapt instructions depending on the level of knowledge of the audience. In other words, either they are novices or experts. The expertise-reversal effect is another illustration of the redundancy effect. Surely, instructional materials support the novice. But they are redundant for the expert and conflict with the automatic recollection of information from their long-term memory.
Redundancy is not repetition!
Redundancy is about unnecessary or replicated information at a given point of time overloading in the instant the working memory. Repetition is the same necessary information repeated at another time in the future. Multiple exposures of trainees to key information is an essential strategy to build long-term memories. Especially when wisely spaced out over time.
Modality effect
Redundancy effect is the same information either coming from the same or from 2 perception channels. On the contrary, modality effect is complementary information coming from 2 perception channels. For instance, via both visual and auditory channels, with as first benefit each perception channel less loaded. As a result, more information can be sent and processed by the working memory.
The second benefit of the modality effect is that it prevents the split-attention effect with all the information at the same moment. For example, the trainer can speak (auditory) and point elements (visual) at the same time.
Transience trap
Mind that the modality effect may lead to the transience trap. Indeed, spoken words may pass a threshold where trainees may have an issue to remember all the transient information. This illustrates that the trainer should find the right balance between the modality and the transient effect as they are in tension. For instance, when using a video, the trainer may mute the video’s original sound. Then he or she narrates himself or herself to provide the right level of information orally.
Dual coding
The modality effect relates to how the trainer presents the information. Whereas dual coding relates to how the trainee stores the information. The modality effect has a side benefit as it enables dual coding. To clarify, dual coding improves the stability of memory as the information is stored in long-term memory in two different but connected ways. In addition, it improves remembering as it builds two separate environmental triggers for that memory to be retrieved: related words or related images.
Worked examples effect
A worked example is a step-by-step demonstration of how to perform a task or how to solve a problem.
Using worked examples is a kind of short cut that borrows from experts. It supports building a well-organized knowledge into long-term memory.
To be efficient with Worked examples, the trainer has to demonstrate at the same time structure and persistence:
- Structure: the trainer has to build worked examples in a way to minimize extraneous load.
- Persistence: the trainer has to use worked examples with trainees even after when it seems that the trainees have understood the underlying concepts.
The most efficient method of studying examples and solving problems is to present a worked example and then immediately follow this example by asking the learner to solve a similar problem.
It contrasts with the usual practice where the trainer spends 20 to 30 minutes of class modelling problems, then have trainees practice in autonomy. Surely, the traditional approach completely overload the trainees’ working memory during this long instructional phase. Then compromise learning. Even, they may get distracted and loose interest.
The good practice for trainer is to ensure only a small amount of variation between example and problem to optimize the cognitive load of the trainees.
Self-explanation based on work examples
Trainees self-explain when they think out loud an example in terms of its underlying principles or why a particular principle can apply to a specific example. The benefits are:
- Connecting examples to their underlying principles allows trainees to see past the surface of a problem so they get the deep structure.
- A principle-based approach makes it possible to transfer to new problems.
Experts categorize problems by their underlying structure, whereas novices classify them by their surface features.
Self-explanation, a good habit for learners
Process-oriented self-explanation helps trainees to check their understanding of the related process or procedure. Really, successful learners keep elaborating hypotheses about what will happen next, whether in a lecture, a conversation, or when reading. Then they read or listen and confirm or infirm if their hypotheses were correct.
Notice: What parts of this page are new to me?
Reason: How does this new piece of information help?
Monitor: Is there anything I still don’t understand?
Self-explanations are more helpful at the beginning of the learning. But the act of self-explaining can overload working memory. So the trainer should use it appropriately.
What’s next? Learn more on training, then coaching and change management
Discover more about training with my post about Training from the back of the room from Sharon Bowman
Check my posts about:
Do you want to learn more about the Cognitive Load Theory? Here are some valuable references
Books on the Cognitive Load Theory from John Sweller:
- Oliver Lovell’s book: Sweller’s Cognitive Load Theory in Action
- Steve Garnett’s book: Cognitive Load Theory
- John Sweller’s book: Cognitive Load Theory
Related Wikipedia pages:
- Overview of the Cognitive Load
- Presentation of John Sweller
- The Gestalt theory